1. 테이블
저장되는 데이터가 key & value가 한 쌍을 이룬다.
키는 서로 다른 데이터를 구별하기 위해 사용되므로 중복되어서는 안 된다.
#include <stdio.h>
typedef struct data{
int number; //사람의 고유번호 = key값
int name; //데이터
}Data;
int main(void){
Data arr[100];
Data person;
int n;
//데이터 넣기
scanf("%d %d", &(person.number), &(person.name));
arr[person.number] = person;
//데이터 찾기
printf("확인하고 싶은 사람의 고유번호 입력: ");
scanf("%d", &n);
person = arr[n];
printf("나이 %d, 이름 %d\n", person.number, person.name);
return 0;
}여기서 사람의 고유번호를 배열의 인덱스로 사용하였다. 여기서 문제점은 고유번호가 클수록 더 큰 배열을 필요로 한다는 점이다. 고유번호가 999999라면 너무 큰 배열이 필요하기 때문에, 함수를 이용해 번호를 변환한다.
이때 사용하는 함수를 '해쉬함수'라고 한다.
2. 해쉬함수
해쉬함수는 키값을 간단한 수로 나타내 주는 함수이며, 키의 특성과 저장공간의 크기를 고려해서 만든다.
예를 들어 f(x) = x%100 이라는 함수가 있고, 위의 코드에서 사람의 고유번호 103일 때, f(103) = 103 % 100 = 3이므로 그 사람의 키 값은 3이 된다. 배열 인덱스 3에 저장되는 것이다.
여기서 발생할 수 있는 문제는 '충돌'이다. 사람의 고유번호가 203인 경우 f(203) = 203 % 100 = 3으로 고유번호가 103인 사람과 같은 키 값을 가지게 된다. 해결방법은 아래와 같다.
1) 선형 조사법(Linear Probing)
충돌이 발생했을 때, 바로 다음 칸을 살펴보고 비었으면 넣는다. 만약 다음 칸도 데이터가 이미 저장되어있다면, 또 그 다음칸을 살펴본다.
f(x)+1, f(x)+2, f(x)+3 ...
하지만 이 방법을 사용하면, '클러스터 현상'이 나타날 수 있다. 즉 특정 영역에 데이터들이 몰려서 분포하는 현상이 일어날 수 있다는 문제가 있다. 이 문제점을 개선한 방법이 '이차 조사법'이다.
2) 이차 조사법(Quadratic Probing)
충돌이 발생했을 때, 바로 다음 칸이 아니라 더 먼 칸을 살펴보는 방법이다. 충돌이 발생한 칸으로부터 $1^{2}$칸 뒤를 살펴보고 데이터가 있으면 처음 충돌이 발생한 곳을 기준으로 $2^{2}$칸 뒤를 살펴본다.
f(x)+ $1^{2}$, f(x)+ $2^{2}$, f(x)+ $3^{2}$ ...
이 방법을 사용할 때는 '슬롯의 상태 정보'도 추가로 관리해야 한다.
데이터를 담을 칸마다 EMPTY, DELETED, INUSE 중 하나로 상태 정보를 같이 기록해두어야 한다.
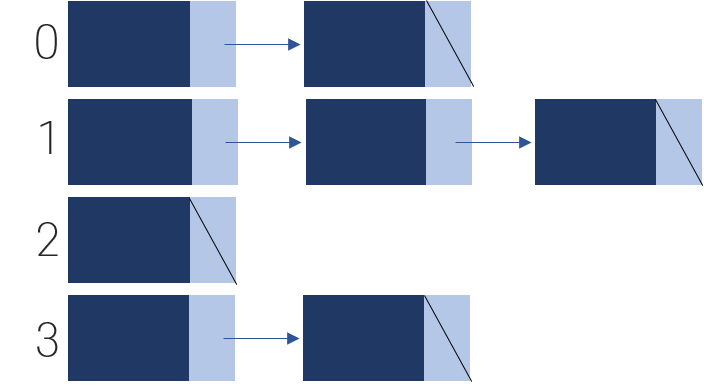
EMPTY와 DELETED를 구별하는 이유는 아래 그림을 참고해서 설명하겠다.


데이터 103이 삭제된 후, 203을 해쉬함수에 대입하여 찾으려면 인덱스 3을 알려준다.
이때 인덱스 3의 슬롯 상태가 EMPTY라면 데이터가 존재하지 않는다고 판단하고, DELETED라면 충돌이 발생하여 선형 조사법이나 이차 조사법을 생각하여 탐색을 진행하라는 의미가 된다.
'이차 조사법'에는 단점이 있다. 충돌이 발생하면 빈 슬롯을 찾기 위해서 살펴보는 위치가 늘 같다는 점이다. 이를 개선한 방법이 '이중 해쉬'이다.
3) 이중 해쉬
충돌이 발생했을 때, 몇 칸 뒤의 슬롯을 살펴볼지도 함수를 이용하겠다는 것이다. 따라서 여기서는 총 2개의 해쉬함수가 필요한 것이다. 아래는 이중 해쉬방법에서 일반적으로 사용하는 식이다.
- 1차 해쉬 함수 h1(k) = k % 15
- 2차 해쉬 함수 h2(k) = 1+(k % c)
1차 해쉬 함수가 %15이므로, 배열의 길이가 15라고 예상한다. 그러면 상수 c는 15보다 작고 소수(prime number) 중 하나로 결정한다. 소수로 결정하는 이유는 소수를 선택했을 때 '클러스터 현상'이 낮아진다는 통계가 있어서라고 한다.
1차 해쉬 함수를 썼을 때 충돌이났고, 2차 해쉬 함수값을 사용한다. 2차 해쉬 함수를 썼을 때도 충돌이 나면, 2차 해쉬 함수에서 나온 값만큼 건너뛰며 살펴본다.
h2(k) => h2(k)+h2(k) => h2(k)+h2(k)+h2(k) ...
4) Chaining
충돌이 발생해도 그 자리에 저장하겠다는 방법이다. 하나의 배열 인덱스에 여러 데이터 즉, 배열을 저장한다고 생각하면 된다.
구현 방법은 두 가지가 있다. 첫 번째는 2차원 배열이고, 다른 하나는 연결리스트이다. 2차원 배열의 경우 충돌이 발생하지 않아도 공간을 마련해놓기 때문에 메모리 낭비가 심하고, 충돌의 최대 횟수가 제한된다는 단점이 있다.
'CS > 자료구조' 카테고리의 다른 글
| 그래프(Graph) (2) | 2021.07.19 |
|---|---|
| 탐색(Searching) (0) | 2021.07.15 |
| 정렬(Sorting) (0) | 2021.07.13 |
| 우선순위 큐(Priority Queue) (0) | 2021.07.11 |
| 트리(Tree) (0) | 2021.07.11 |